Kubernetes集群控制面核心组件高可用原理。
介绍etcd和Raft协议,以及在etcd之上实现kube-controller-manager、kube-scheduler高可用。然后提出了利用keepalived和haproxy使kube-apiserver实现高可用和负载均衡的方案。
高可用
系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统与构成该系统的各个组件相比可以更长时间运行。
高可用性通常等同于消除单点故障,提高系统的容错能力。对于k8s集群来说,由于集群本身具有任务调度的机制,部分node节点的故障并不会造成整个系统变为不可用的状态,所以集群的高可用主要指master节点上各主要组件的高可用,包括etcd、kube-controller-manager、kube-scheduler、kube-apiserver。这些组件如果故障,就会影响集群整体功能,因此必须要提高各组件的容错能力,部署冗余的备份,当少部分主机或进程故障时,使得其他备份组件能照常实现系统完整的功能。
etcd
etcd is a etcd,是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。在集群中,etcd保存了集群所有的网络配置和对象的状态信息,如果etcd发生故障,将直接导致整个集群故障。
etcd在集群的master节点上,作为静态pod,直接由kubelet启动,每个节点只有一个实例,要实现etcd的高可用,需要多个主机分别运行多个etcd实例,通过数据同步组成集群实现高可用。
etcd集群内部采用Raft协议作为共识算法进行分布式协作,将数据同步存储在多个独立的服务实例上以提高数据的可靠性,从而避免了单点故障所导致的数据丢失。Raft协议通过选举出的Leader节点来实现数据的一致性,由Leader节点负责所有的写入请求并同步给集群中的所有节点,在半数以上节点的确认后持久存储。参考Raft协议的动画展示,形象地说明了节点间的通信流程 Raft Understandable Distributed Consensus
日志复制
在etcd这类分布式数据系统中,节点之间的数据同步本质上是日志复制的同步。在多个节点的etcd中的数据并不是一次性写入的,而是被不断修改更新,由每个节点上的状态机来保证每一份副本处于相同的状态,即使其中部分节点处于故障状态也能持续工作,这类系统称为复制状态机(Replicated State Machines)。多个节点之间的数据通过日志复制(Log Replication)来实现一致性。每个节点存储包含一系列命令的日志,由状态机按顺序执行。每段日志包含相同的命令,以相同的顺序执行,因此每个状态机都处理相同的命令序列,最终每个节点状态机都会得到相同的状态和相同的输出顺序。
节点状态
在etcd集群中,节点存在三种状态:
- Leader
- 接收客户端请求,然后根据协议将数据同步到其他节点
- Follower
- 不主动发出消息,只是被动接收Leader的更新消息。如果直接接收到了客户端请求,会直接将请求将转发到Leader
- Candidate
- 当Leader下限时,Follower转变为参与选举
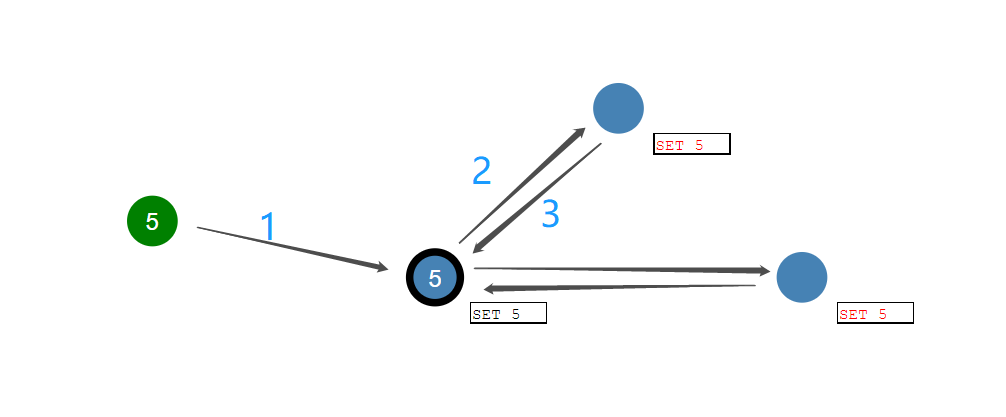
图中左侧节点为Leader,另外两节点为Follower。客户端发出的所有请求都将由Leader接管,正常情况下,Leader将请求的命令通过日志发送到每一个Follower。当Follower接收到消息后,将数据写入自己的日志并告知Leader接收成功,Leader在收到多数节点的回复后,确认命令执行正常。
选举
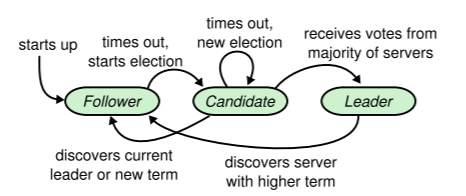
Leader和Follower之间通过心跳消息保持连接。如果Follower在一段时间内没有收到来自Leader的心跳,就会转为Candidate,参与新一轮选举。
集群初始化的时候,内部的节点都是Follower节点,都在等待Leader的心跳,这里的超时时间是个随机数,因此会有一个节点首先因为没有收到心跳而转为Candidate,发起选主请求。当这个节点获得了大于一半节点的投票后会转为Leader节点。
当Leader节点服务异常后,其中的某个Follower节点因为没有收到Leader的心跳转为Candidate节点,发起选主请求。只要集群中剩余的正常节点数目大于集群内主机数目的一半,就可以正常选举出新的Leader,集群就可以正常对外提供服务。
故障场景
TODO
Controller Manager
kube-controller-manager是一个守护程序,作为Kubernetes核心控制回路的一部分。 在自动化应用场景中,控制回路是一个永不停止的循环,用于调节系统状态。对应的在Kubernetes中,controller作为一个控制回路,负责持续监视集群的状态,并通过apiserver动态调节集群组件,以达到需要的状态。 当前Kubernetes集群中的controller包括replication controller、endpoints controller、namespace controller、serviceaccounts controller等。
kube-controller-manager在每个master节点都会有一个实例在运行,但其中在同一时刻只能有一个实例处于工作状态,多个实例同时工作并不会提高效率,反而可能会造成同一行为重复执行。所以除了排除单点故障外,还必须保证Leader唯一。
由于运行在集群之中,而集群的etcd和apiserver的高可用已经另有保障,所以kube-controller-manager不需要再独立实现一套高可用方案,实际是借用集群的Endpoints资源来实现锁机制,保证高可用并维护Leader的竞争。
Resource Lock
Leader通过分布式锁机制来实现,维护Endpoints资源对象来实现锁状态。集群启动时,各kube-controller-manager实例通过竞争的方式去抢占指定的 Endpoints资源锁。只有一个胜利者可以获得锁,将成为Leader,通过更新Endpoints的annotations,将自己的节点名写入control-plane.alpha.kubernetes.io/leader注解的holderIdentity的值,并周期性更新注解中的renewTime以声明对锁的持有状态,从而避免其他节点的实例进行争抢。当Leader出现异常,就不会再更新renewTime了,处于等待状态的其他各节点实例就将开始尝试获取锁,进行新一轮的竞争。这样就利用了Endpoints资源,轻易的实现了分布式的锁机制。
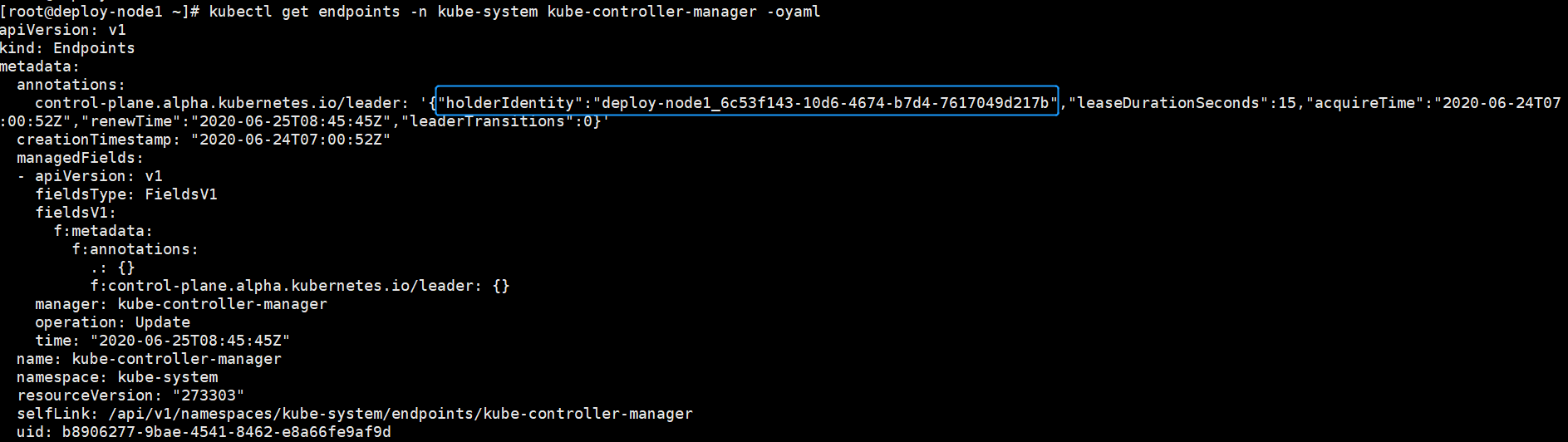
加锁操作的原子性由resourceVersion来保证。所有通过apiserver对资源对象的操作,都具有原子性,包括Endpoints资源。资源对象有一个 resourceVersion 字段,用于标识资源版本,每次更新操作都会递增这个值。当尝试获取资源锁的时候, 需要更新Endpoints资源,请求会携带resourceVersion 字段,apiserver在更新资源前,会通过验证当前数据库中的resourceVersion 的值与更新请求指定的值是否相匹配,来确保在此次更新操作周期内没有其他的更新操作,从而保证了更新操作的原子性。当第一个请求成功更新Endpoints资源后,后续的竞争者的请求会因为resourceVersion不匹配而被拒绝,从而实现只有一个胜利者可以获得锁。
Scheduler
kube-scheduler是kubernetes的调度器,作用是根据特定的调度算法和调度策略将Pod 调度到合适的节点上。监听kube-apiserver,查询还未分配Node的Pod,然后根据调度策略为这些Pod 分配节点。
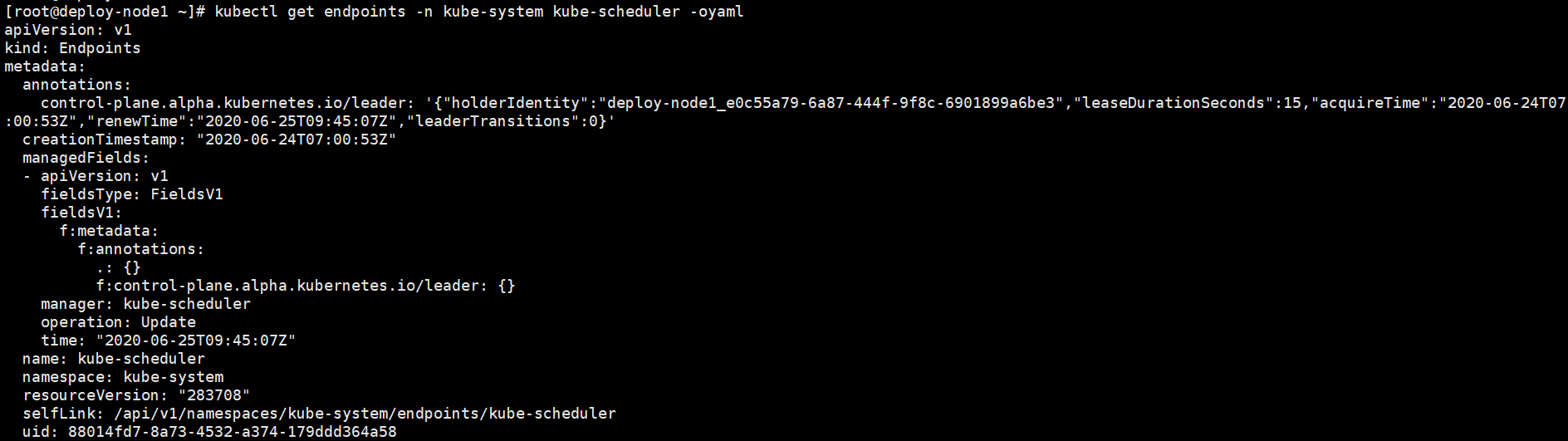
kube-scheduler的高可用机制与kube-controller-manager是相同的,同样利用Endpoints实现资源锁,保证高可用并维护Leader的竞争。
Apiserver
默认安装的k8s集群,并没有支持kube-apiserver的高可用。虽然每个节点都有kube-apiserver的实例,每个实例也都可以独立接受请求并实现集群资源操作,但是并没有实现完整的高可用机制。比如在外部访问时,需要指定某一个master节点的IP作为访问地址,如果这个master节点处于故障状态,那么这个IP地址的API就是不能访问的,需要客户端手动更换地址到另一个master节点的IP再进行尝试。这不是一个完整的高可用系统。
在实际使用环境中,可以通过keepalived的vip机制来保证可用性,并加入haproxy实现负载均衡。
keepalived
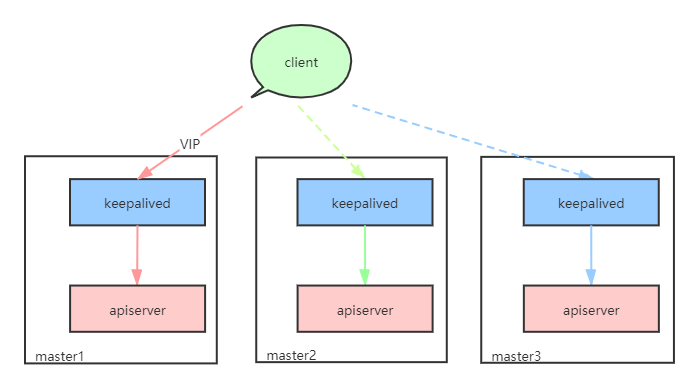
在高可用部署时,通过static pod在每个master节点部署keepalived。keepalived通过VRRP协议在master节点之间维护一个虚拟IP,VIP(Virtual IP address),控制几个master节点组成一套高可用主备系统。整套主备系统包括一台为主节点MASTER,其余为备份节点BACKUP,但是对外表现为一个VIP。这个VIP是一个原本不存在于网络中的IP,会被keepalived自动被添加到MASTER节点的网卡上,此时MASTER节点应当有2个IP地址:原本的主机IP,和由keepalived添加的VIP。VIP会作为一个普通的IP地址,接受网络请求,相当于客户端不需要知道有几个节点,也不需要知道各自的主机IP,只认为有一个VIP节点,通过VIP就可以连接apiserver。
keepalived的作用就是在节点间维护VIP,持续检测当前节点的apiserver工作状态,根据是否健康计算出当前的权重优先级,向其他节点发送自己的权重优先级。如果MASTER节点优先级降低,而另一个BACKUP节点优先级更高,那么身份就会切换,VIP就会绑定到新的MASTER节点上。这样就在客户端没有感知的情况下,将apiserver的接入从故障节点切换到正常节点。
haproxy
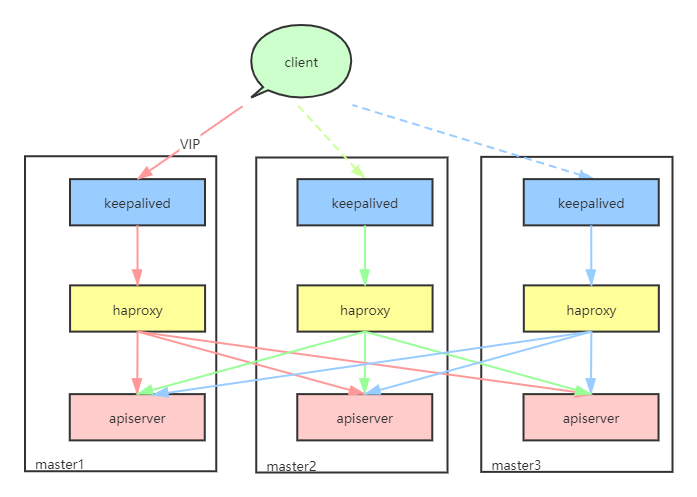
上述结构在引入了keepalived之后,可以实现集群kube-apiserver的高可用,不过有一个不足之处,只有一个实例处于工作状态,其他节点的kube-apiserver不会被来自VIP的外部请求访问。
与kube-controller-manager不同,kube-apiserver是可以多个实例同时工作的,既然有多个节点,就可以通过负载均衡机制分担任务压力,避免因为请求过多而造成性能下降和故障。
引入haproxy作为负载均衡器,同时保留keepalived保障多个haproxy实例的高可用性。同样由keepalived维护VIP,不过原本apiserver的端口6443改为由haproxy接管,无论此时VIP绑定到哪一个节点,haproxy都会将请求平均的分配到多个不同节点的apiserver,从而在高可用的基础上,实现了负载均衡。